How to Screen B2B Prospects Automatically Using a Web Spider
December 18, 2013
Here at OpenView, we understand how important qualifying prospects is to scaling success for our portfolio companies. In this post, we’ve outlined how to screen B2B prospects automatically using a web spider, from defining the right customers to optimizing your approach and algorithm.
Table of Contents
- The Problem: How Can You Efficiently Screen Large Numbers of Prospects?
- Our Solution: Cheaply Screen Prospects Using Automation
- Step 1: Define What You’re Looking For
- Step 2: Hypothesis Building
- Step 3: Building the Feature Extractor
- Step 4: Training the Algorithm
- Step 5: Running the Spider at Scale
- Step 6 and Beyond: Optimizing the Feature Extractor and Algorithm
“How do I find more customers?”
As the principle concern of the sales and marketing function at any company, many of our portfolio companies ask OpenView Labs this question.
Our companies are generally at the stage where they’ve achieved some degree of product-market fit, and are looking for a way to scale this success. While many continue to experiment with new products, delivery models, channels, or markets, the most obvious source of new customers is usually to look at the type of customers they’ve had success with, and find more of them.
Finding the necessary information to qualify or disqualify a large enterprise isn’t always easy, but can usually be accomplished with old-fashioned detective work on specialized third party company information websites like Data.com, LinkedIn, Edgar, and Builtwith. There also aren’t that many big companies out there, so finding and screening them manually isn’t prohibitively time consuming. As a primarily B2B-focused VC, most of OpenView’s portfolio companies fall into this enterprise category.
The Problem: How Can You Efficiently Screen Large Numbers of Prospects?
On the other end of the spectrum, several companies in our portfolio sell to the massive and diffuse SMB market, with hundreds or thousands of customers and a target market in the tens of thousands.
When one of these companies presented us with the typical “How do I find more customers?” question, we couldn’t use the manual approach we often employ for enterprise software. They had too many customers to go through by hand, and those customers didn’t generally show up in the third party directories we use to research enterprise prospects. There was the additional looming problem of discovering more of them; for every characteristic we painstakingly researched by hand, if we ended up using it as a qualifying feature, we would have to collect it for every potential prospect we sought to qualify, which would be close to 100,000.
Where that usually means hundreds of hours of research and data entry for our offshore research teams, for this company it would be thousands of hours. That’s not an acceptable expenditure of resources for our team, or for the portfolio company, as they planned to ultimately take control of the process.
Our Solution: Cheaply Screen Prospects Using Automation
Since manual qualification wasn’t an option, we instead looked for an automated approach.
While their typical prospect shows up inconsistently in third party directories and data-sources, it does usually have a very basic website, which is quickly becoming common even in the most low-tech, brick-and-mortar small businesses. By automatically analyzing these websites using a web spider, we saw an opportunity to help cheaply pre-screen prospects for their sales and marketing function.
From a high level, a web spider built for this purpose needed to have two major components:
- A feature extractor that crawls prospect websites and extracts pre-specified features, such as the number of links, incidents of a certain keyword or HTML element, etc.
- An algorithm (a.k.a. classifier model) that makes sense of those features and spits out a label, in our case simply “good prospect” or “bad prospect”.
This blog post describes the multi-step process for developing a system to automatically screen prospects based on their website.
Step 1: Define What You’re Looking For
In order to build a model to screen prospects for our portfolio company, we first needed to think carefully about both the type of prospects we wanted, and the type(s) we would likely come across and want to disqualify. Their CRM was the ideal place to start. CRMs are a fertile source of leads that have already been qualified by hand out of necessity, and these classification tags can be repurposed to train your algorithm.
We worked with sales and marketing leaders at the portfolio company to define which lead statuses should be considered “good,” which should be considered “bad,” and which were inconclusive, because they could never get in touch with them to qualify or disqualify them as an opportunity. Next, we agreed on a reasonable timeframe that was recent enough to be relevant to the current market conditions, but not so recent that the majority would still be in the sales cycle. We pulled a list from their CRM of the ~3,000 leads that were either considered good or bad and met the timeframe requirements. This list would serve as our training input set (and training labels) in the diagram above.
Step 2: Hypothesis Building
Armed with a training dataset of resolved leads, our attention turned to extracting a list of features that could potentially be used to predict whether the training leads were good or bad. I say “potentially,” because without having modeled the data, ideas about what might be predictive were only hypotheses, and would have to be tested for efficacy.
This is the phase of the project where domain expertise is most important. To come up with ideas for predictive website features, we leaned on the company’s sales and marketing function and their vast experience with customers and prospects of all shapes and sizes. To get to this information, we asked some of the following questions:
- What are some characteristics of good leads?
- What are some characteristics that can disqualify a lead?
- Are there any leads that initially seem good, but drop out later in the process? Why?
- What does your typical lead’s website look like?
- When you’re browsing a prospect’s website, which pages do you navigate to, and what do you look for?
At this point, we very much cast a wide net — any ideas from the portfolio company would have to be tested anyway, so there was no real harm in including what might seem like a far-fetched theory. This gave us a long list of website features including features related to the company, technical features related to the website’s design and architecture, and keywords that they believed should or shouldn’t show up on a prospect’s website.
Step 3: Building the Feature Extractor
Next, we had to get our hands dirty actually pulling proxy data related to these hypotheses from a prospect’s website.
The feature extractor we built was about 500 lines of Python (it’s since been gradually expanded to about 700 as we added more features and fixed bugs). It begins by crawling the homepage of a prospect website, handling and documenting redirects, collecting a list of internal links, and processing the meta-data for about 120 keywords. Next, it visits each of the level one links — internal pages linked directly from the homepage — to continue searching for keywords that might be buried in an “about us,” “services” or “products” page. The spider takes about 15 seconds to run per URL and produced a rich set of features related to the prospect’s website.
While I won’t go into detail on the actual keywords for competitive reasons, I’ll provide a fabricated example to illustrate this process. Let’s say your software is a point of sales system designed specifically for ice cream shops. Below, I’ve listed five hypotheses your sales team might have come up with, and how the feature extractor would test them:
| Hypothesis | Test |
| The shop will mention ice cream or related terms on the homepage | Search the home page and meta data for keywords “ice cream,” “frozen yogurt,” “fro-yo,” “fro yo,” “frozen banana,” and “waffle cone” |
| Many Ice Cream shops sell a particular brand of ice cream | Search the entire website for “Ben and Jerry,” “Ben & Jerry,” “Cold Stone,” “Klondike,” and “Haagen Dazs” |
| Ice cream shops tend to have a menu on their website with prices | Search the website’s text for the term “menu” and the character “$” |
| Ice Cream shops generally have small websites. Larger websites usually belong to an ice cream manufacturer or general grocery store | Count the number of internal links on the homepage, the number of text words, and the combined number of HTML characters on all of those links (all a proxy for the size of the website) |
| Most ice cream shops have Facebook pages | Search for a link to Facebook on the website’s home page |
This isn’t the only possible way to extract features. Alternatively, the feature set could contain all of the words in the website’s text, and use an unsupervised Naïve Bayes algorithm to model the data. If you prefer, it could only evaluate the homepage, or alternatively, go deeper than level one links to capture more of the website. It could even use some abbreviated version of the website (for example, this text extraction API: http://boilerpipe-web.appspot.com/).
For starters, any of these methods will probably be better than nothing, but if you’re looking to optimize your algorithm, you may need to compare multiple methods, and that includes modifying or increasing the number of features extracted.
Step 4: Training the Algorithm
Training the algorithm requires some statistical expertise. More specifically, your approach to modeling the data should depend on the shape and type of the data produced by your feature extractor.
In this case, we generally had continuous independent variables—mostly keywords counts—and a binary dependent variable: “good” or “bad.” However, because many of the keywords were correlated, we clustered collinear keywords into groups (generally, these groups matched up to a specific hypothesis) before running a series of regressions using our keyword groups rather than individual keywords.
This phenomenon is illustrated best in a correlation matrix. Here, I took 0.5 as the threshold for meaningful correlations, and considered multiple adjacent correlations to be ‘clustered.’
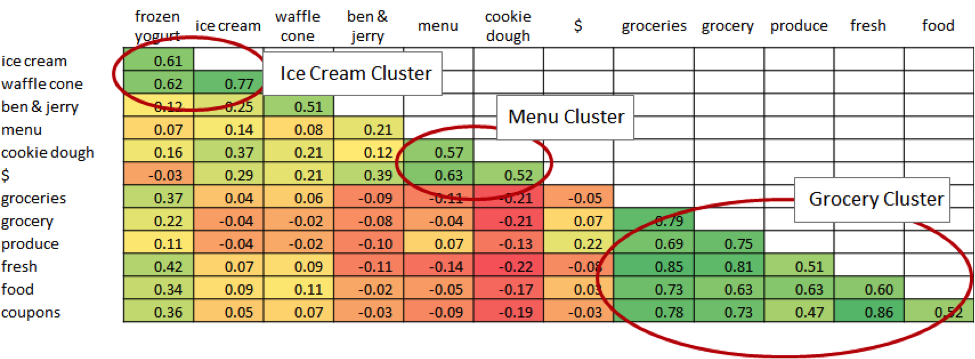
The winning model was a logistical regression with 11 dependent variables, primarily related to keywords on the website and in its metadata, and accurately categorized a test set about 70% of the time.
While we ultimately decided on a logistic regression, we tried both Naïve Bayes and linear regressions using transformed data as a means of comparison. We found these alternative models to be slightly less accurate than the logistic model, but much more complicated and difficult to interpret. A hybrid model, using each of the three models as inputs, was only marginally more successful than the logistic regression on its own, so the idea was scrapped in favor of the much simpler single model.
After fitting the algorithm, the spider was amended to calculate it for each prospect it qualifies. After making this modification, when the spider crawls a prospective customer, it returns not only the raw data from the feature extractor, but also its prediction as to whether a lead is more likely to be good or bad.
Step 5: Running the Spider at Scale
Now that we can automatically tell (with reasonable accuracy) whether a prospect fits into their target segment based only on its website, how do we make use of this process?
There are several ways we’ve used the spider on behalf of our portfolio company since developing it:
- Prioritizing dormant leads in their database. The company’s CRM contained a large number of leads that they didn’t feel were worth pursuing, either because they were too old or came from lower-quality sources and would require a lot of manual review to pull out the few good ones. The spider was able to quickly mine a large number of these and extract a few good ones that had been long ignored.
- Screening inbound leads. Like most B2B companies, the company uses gated content on their website to generate inbound leads. Running inbound leads’ email domains through the spider can help screen out junk or fake leads before they require attention from a salesperson.
- Producing outbound leads. In addition to inbound interest, the company generates leads by actively identifying and reaching out to prospects. The spider has proved tremendously useful at screening companies found on a directory for their relevancy as outbound sales prospects.
Step 6 and Beyond: Optimizing the Feature Extractor and Algorithm
After a few months of qualifying leads with the same algorithm, your employees will inevitably start to notice common errors in your spider’s output. While small changes can be made on the fly (for instance, moving long-tail keywords from one keyword group to another, or fixing a technical error), I’d recommend recalculating the algorithm if you make any considerable changes to the feature extractor.
In our case, we overhauled the algorithm after roughly a year of operation. Because we had more experience and more data to work with, we were able to improve its accuracy by about 19%. If we re-calculate it again a year from now, I’d expect the results to improve by another few percent.
Alternatively, a more continuous approach would be to maintain both a production and development version of the spider, updating the production spider only when the development algorithm is able to beat the prior production model. If you want to get really sophisticated, you could create a true machine learning system that automatically incorporates new data into the algorithm, but this is probably more of an enterprise solution than an expansion-stage one.
Post-Development
Post-development, the spider takes very little time to run, processing thousands of companies per day, and requires very little human supervision. While it’s inevitably going to make its share of errors, the ability to pre-screen prospects before they ever have to be manually reviewed has been a considerable time-saver for the portfolio company and has allowed their salespeople to spend their time in more productive ways, namely, selling their product to more qualified prospects, rather than constantly reviewing their websites.
One Word of Caution
You will need a considerable amount of data for this to be worth it. If you only have a handful of customers, you’ll likely spend more time developing a mediocre algorithm than you would simply reviewing them by hand. I’d only consider this approach for companies that have hundreds or thousands of customers, and a prospective market in the tens of thousands.
Likewise, if you have a strong reason to believe a company is a good target, the spider may do more harm than good depending on its error rate. We generally consider high-quality lists pre-qualified, and only run the spider when the source’s quality is medium to low.
While this process is very much a work in progress, it does work, and we’ve learned a ton in the process of developing it. If you’re curious for more technical details on how you can get started, please don’t hesitate to email me (my address is listed on the website)
Photo by Paul Gagie